

One of the goals of malware authors is to keep their creation undetected by antivirus software. One possible solution for this are crypters. A crypter encrypts a program, so it looks like meaningless data and it creates an envelope for this encrypted program also called a stub. This stub looks like an innocent program, it may also perform some tasks which are not harmful at all but its primary task is to decrypt a payload and run it.
Why is this one intriguing?
The crypter discussed in this blogpost uses a combination of multiple interesting techniques that make it hard for analysts and for proper detection. One of the key techniques this crypter uses is multiple layers of encryption. Because of this we are calling it “OnionCrypter”. It’s important to note the name reflects the many layers this crypter uses, it’s in no way related to the TOR browser or network.
This blogpost covers most of the techniques OnionCrypter used to complicate analysis and breaks down its structure. This can help malware analysts because seeing samples like these might get confusing and overwhelming at first not only for humans but also for dynamic analysis sandboxes.
Most interestingly, we have found that OnionCrypter has been used by over 30 different malware families since 2016. This includes some of the best known-most prevalent families such as Ursnif, Lokibot, Zeus, AgentTesla, and Smokeloader among others. In the last three years we have protected almost 400,000 users around the world from malware protected by this crypter. Its widespread use and length of time in use make it a key malware infrastructure component. We believe that likely the authors of OnionCrypter offer it as an encrypting service. Based on the uniqueness of the first layer it is also safe to assume that authors of OnionCrypter offer the option of a unique stub file to ensure that encrypted malware will be undetectable. A service like this is frequently advertised as a FUD (fully undetectable) crypter.

OnionCrypter forms a malware family on its own, even though it is used to protect malware from many different families. OnionCrypter has been around for several years so it is not something entirely new, however it is interesting that because of the multiple layers and uniqueness of the first layer, nobody was detecting this crypter as one malware family. After downloading thousands of samples of this crypter from VirusTotal, we were able to confirm that most of the detections from all AVs are based on detecting what’s encrypted inside this crypter. Even when AVs are recognizing the samples as a crypter with some other malware packed inside, they are detecting the samples as tens of different malware families.
Statistics
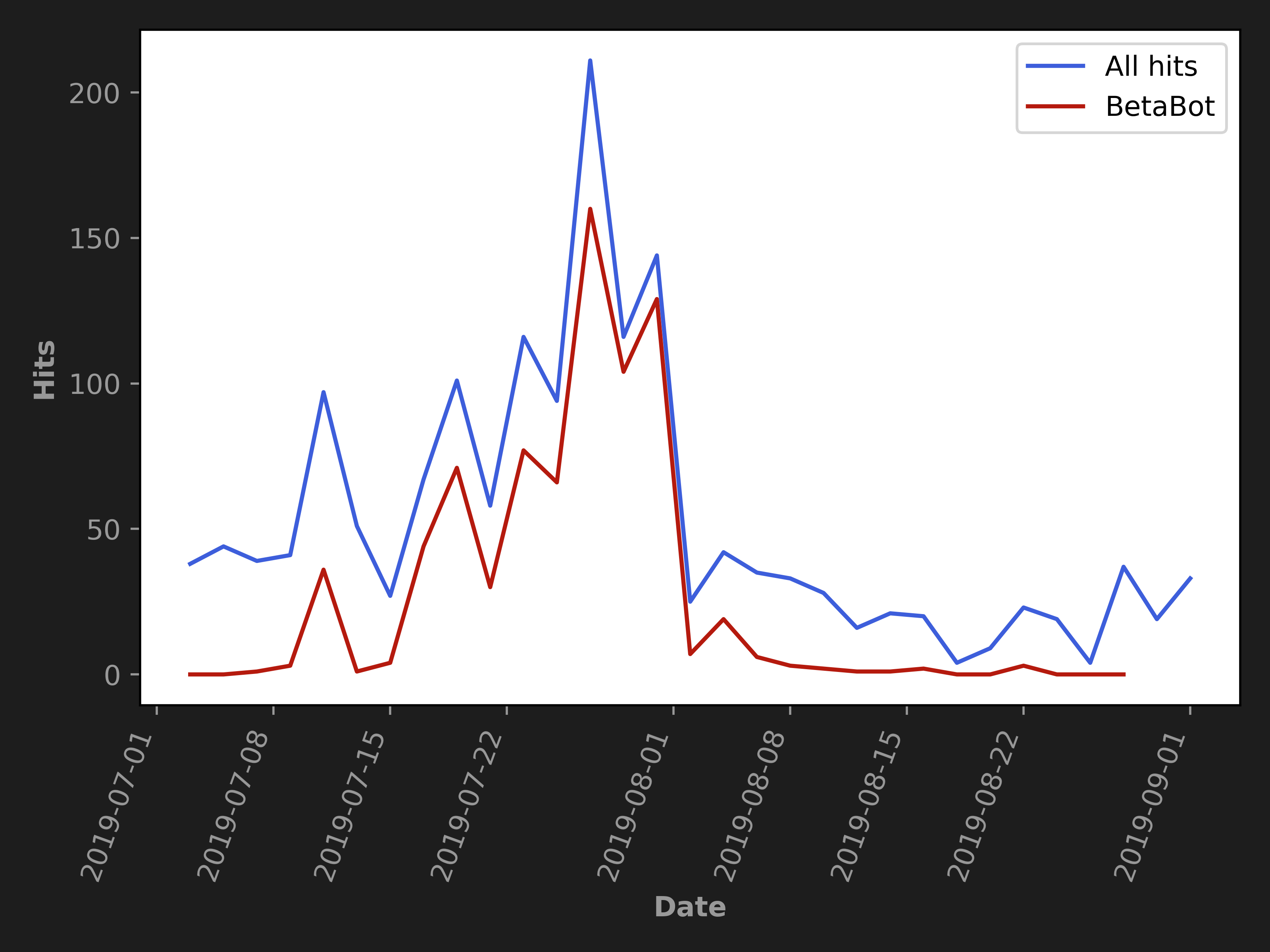
With the data from more than 15,000 samples (where oldest samples date back to 2016) it was possible to create a statistic on malware families which are using this crypter. The chart below shows that OnionCrypter is used by multiple malware authors.

With the same data it was possible to create graphical insight on prevalence of the crypter during its existence.

This data can be further interpreted. The peaks suggest that in that time period there could have emerged a new malware campaign which was using services of the OnionCrypter and was spreading widely through the world. After a closer look at the highest peak and identification of malware families inside the OnionCrypter encrypted samples, it was possible to confirm that this peak corresponds to the spread of BetaBot malware family, a family that spreads ransomware and other malware, during the summer of 2019.
Analysis
OnionCrypter is 32-bit software written in C++. Architecture of OnionCrypter consists of three layers. Each layer will be discussed in a separate section along with techniques which can be found there.
Layer 1
This is the outer layer of OnionCrypter. Even though the first layer includes usually at least a few hundred functions, there is always one long function (let’s call it main function) with a lot of junk code but it also includes following functionalities which are important parts of OnionCrypter:
- Creation of a named event object
- Allocation of a memory
- Load data to memory
- Decrypt of the loaded data
- Pass execution to decrypted data
The easiest way to find this function is to check cross references to the CreateEventA API function.
Uniqueness
After finding this main function in multiple samples there is the first obstacle – uniqueness. Each one of the analyzed samples had a unique main function. Differences vary between big ones like completely different API function calls in the junk part of code or small ones like those that use different registers and local variables in a cycle which seem the same. As a consequence, creation of static rules for detection gets quite complicated if someone wants to cover the majority of samples.
After seeing some samples it is possible to quite easily estimate which function is the main function. The main function is always quite long, because of junk code and often because of loop unrolling. It may happen that memory allocation or decryption happens in a small part of code between unrolled iterations of loops full of junk code.

From left to right
260003293D1785571FEF5A2CF54E89B7AF0C1FBD5B970D2285F21BFC65E2981C
05AAB2F7D5D432CBEB970BC5471B3FAE1E45F23E0933CC673BE923F7609F53AE
17C2E36EE4387365AC00A84E91B59CE4D31D3BA04624902512810B7797A2356B
81C479BF71196724055F1AF30CA05C9162B7D32E7B3363B7F93D1AAF0161E760
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
In many cases one or more sleep calls (sleep function from synchapi.h) are included in the junk code. These sleep calls along with loops that have many iterations can increase execution time by a few minutes. This can cause some simple dynamic analysis sandboxes to fail. Even when a sandbox is able to detect the final payload and scan it with Yara rules, it is often necessary to increase timeouts to 3 or more minutes.
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
UPX impostors
One of the most common packers is the UPX packer which can compress programs and also hide their original code. A few samples have the first layer modified to look like they are UPX packed even when they are not. At the first glance it is possible to see that the sample has sections exactly like UPX, even when you analyze the sample with tools like “Detect It Easy”, the tool will incorrectly tell you that the sample is UPX packed.
This can lead to the confusion of an inexperienced analyst, but what is even worse it can confuse analytical tools. There are multiple tools for automatic and static unpack of UPX packed programs and for extraction of original code for further analysis. When a tool like this unpacks an UPX impostor sample the result will be random corrupted data. On data like this any static detection will not be possible and a corrupted sample won’t run in dynamic analytical boxes.
Exceptions
The majority of samples raise exceptions during debugging. In most cases it happens at the beginning of the main function. Dealing with these exceptions can slow down manual analysis and definitely make dynamic analysis more difficult. It’s a good idea to identify the place where exceptions are raised, because even if some samples are throwing only a few exceptions, others do it in a loop and passing them one by one may be too time consuming.
The most common exceptions which could appear are:
- Microsoft C++ exception with code
0xE06D7363- This exception is usually thrown by some exotic functions used in junk code. Some of the functions causing this exception are:
SCardEstablishContextSCardConnectASCardTransmit
- This exception is usually thrown by some exotic functions used in junk code. Some of the functions causing this exception are:
- Instruction referenced memory at
XYZ. Memory could not be read. Exception code0xC0000005 - Unknown exception code
0x6EF- From function
GetServiceDisplayNameA
- From function
We have also found that OnionCrypter combines functions that throw exceptions with the data about the position of the mouse cursor. OnionCrypter uses a loop where it finds out the cursor position (X and Y coordinates) using the function GetCursorPos and compares it with the position values from the previous iteration of the loop. If the X or Y coordinate didn’t change, the program calls more functions that throw the exceptions, waits for a few seconds and starts the next iteration of the loop. It is expected from a normal user that he will move his mouse during this timeframe, but it is not expected from a sandbox or analyst who is pressing the F9 key repeatedly to pass the throwing exception part of the program. Because of that we believe that throwing the exceptions is an anti-debug trick to make the manual work of analysts harder.
Named event object
OnionCrypter uses named event objects, which are hardcoded into the code and created in the main function to avoid multiple executions of the payload. This feature is important for the malware hidden inside, because many times can multiple simultaneous executions of particular malware on one device cause some unexpected or unwanted behavior (e.g. there is no need to run the same ransomware twice on one device). After deeper analysis it was possible to connect multiple event objects to this particular software.

8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
To facilitate extraction of new names of the event object and to automate processing, an IDAPython script was created. Among most common names of event objects are:
- milsin
- svet
- lifecicled
- parames
- cueevn
- Strolls
- Menulapkievent
- doroga
Allocation of memory
At some point during the execution of the main function OnionCrypter has to create the memory space where it loads and decrypts data. Another aspect of uniqueness is demonstrated here. For allocation OnionCrypter uses one of the following functions:
GlobalAllocVirtualAllocHeapAlloc
In other malware families it is normal that samples of a crypter belonging to the same family use the same memory allocation function across all samples. In this case there are three different functions. This complicates analysis and it is another anti-analysis trick to hide the payload, because it is not enough to hook one function and monitor allocated memory in order to find the payload. What is even worse, hooking all these functions may be a very slow way to find allocated memory, because the important allocation happens in some part of the junk code. At the same time, during execution of the junk code, allocation functions may be called many times to allocate insignificant memory. Especially when these functions are used in a loop, monitoring all allocated places will be overwhelming. One possible solution to solve this is the knowledge that the allocated memory for the encrypted data has all three of the read/write/execute flags set to true. With some cleverly placed breakpoints in main function and monitoring of memory segments it is possible to find a moment when a segment with read/write/execute flags was created.
Decryption of the second layer
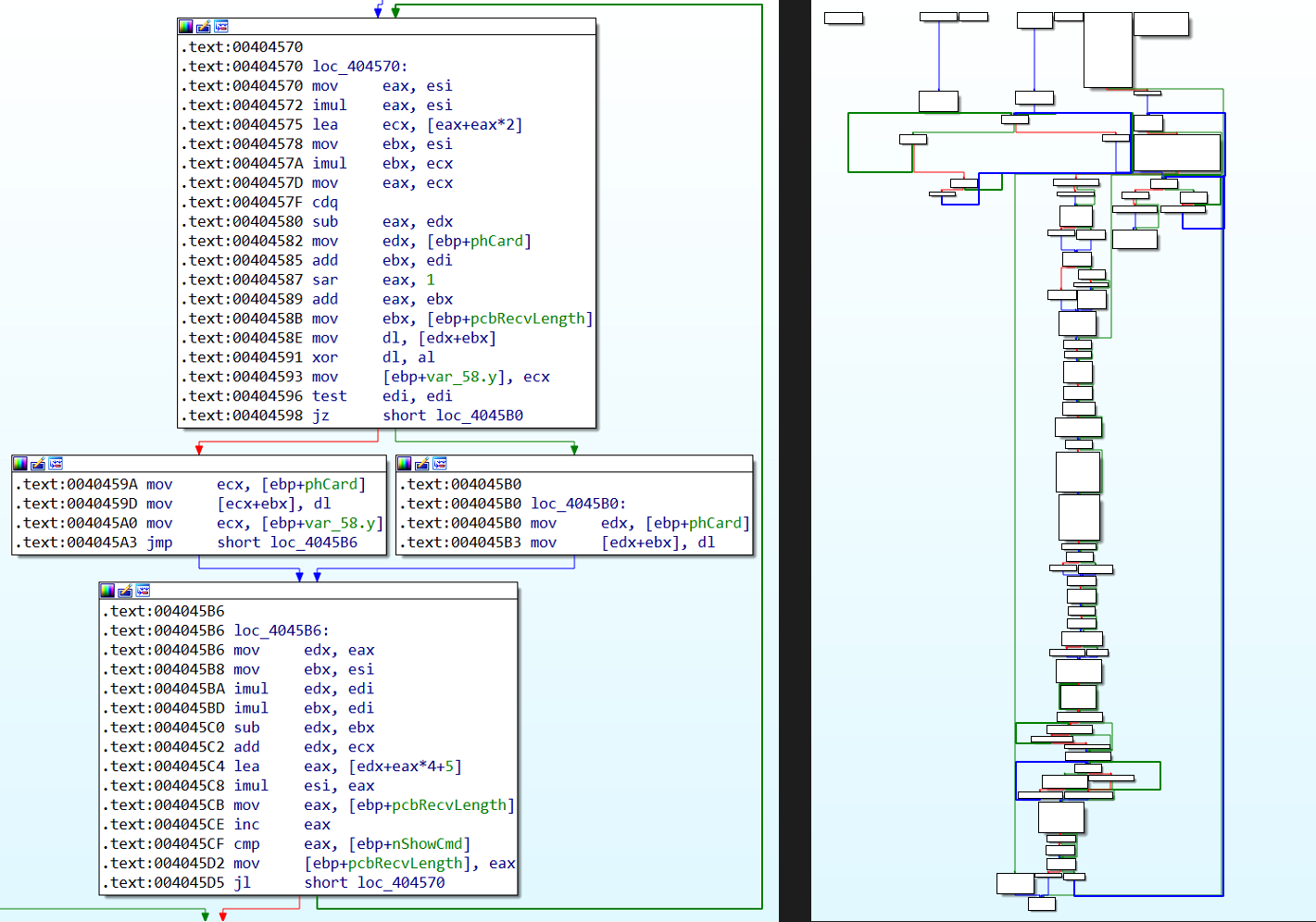
After memory allocation, data is moved into created space and decrypted. Either a decrypt loop is implemented inline in the main function or a separate function is called. Finding the decrypt loop is easy with an R/W breakpoint for allocated memory. Even here every sample is quite unique. Even though all samples read data byte by byte and xor it with another value, implementation of the decrypt algorithm is totally different, as can be seen in the images below.
left – 75E692519607C2E58A3E4F5606D17262D4387D8EEA92FAB9C11C64C4A6035FBC
right – 8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
On the left side the decrypt algorithm of layer 2 is implemented as a part of the main function. This algorithm is quite simple – it uses one byte as a key value and does XOR operation on all bytes of encrypted data. What is even more interesting, this algorithm is so naive, that if the key was originally set to zero, layer 2 would not be (de/en)crypted at all.
On the other hand the decrypt algorithm on the right side is quite complicated. It is a standalone function, which receives as parameters pointer to the encrypted data, length of the encrypted data and key seed value. Decryption goes from the beginning of the encrypted data and it does XOR operation of key value and each encrypted byte. Unlike the previous decrypt algorithm, this one is a stream cipher, which generates a key stream. Key stream consists of key values where a new key value is generated from a key value used in the previous iteration.
Passing execution to the second layer
Even here are some creative ways of how to start the execution of the decrypted code. The simplest, which is also the most frequent one, is to load a pointer to the decrypted code into the register and call it.
Things can get more interesting when there is no call to a register. Some samples use “Enum” functions like EnumSystemLanguageGroupsA to pass execution. Originally this function enumerates the language groups that are either installed on or supported by an operating system, but one of the parameters of this function is a pointer to an application-defined callback function. This callback function should process the enumerated language group information provided by the EnumSystemLanguageGroupsA function. Instead of providing a pointer to the callback function a pointer to the decrypted code is given as parameter and as a result decrypted code gets executed.

909A94BCB5C0354D85B8BDB64D4EE49093CCA070653F73B99C201136B72CB94A
A similar technique is used with all kinds of “Enum” functions e.g. CertEnumSystemStore or EnumDisplayMonitors. Because of the amount of these functions and possibility of their legitimate use, it is not feasible to detect OnionCrypter by this technique.

846DCC9BCDC5C6103B2979FF93F4E1789B63827413B2FE56B1362129DF069DAF
List of functions known to be used by OnionCrypter:
EnumSystemLanguageGroupsACertEnumSystemStoreEnumDisplayMonitorsEnumObjectsEnumFontFamiliesAEnumTimeFormatsAEnumDesktopsAEnumerateLoadedModulesEnumDateFormatsAEnumPropsAEnumFontsAEnumSystemGeoIDEnumWindowStationsWEnumResourceTypesAacmFormatEnumAEnumSystemCodePagesW
Layer 2
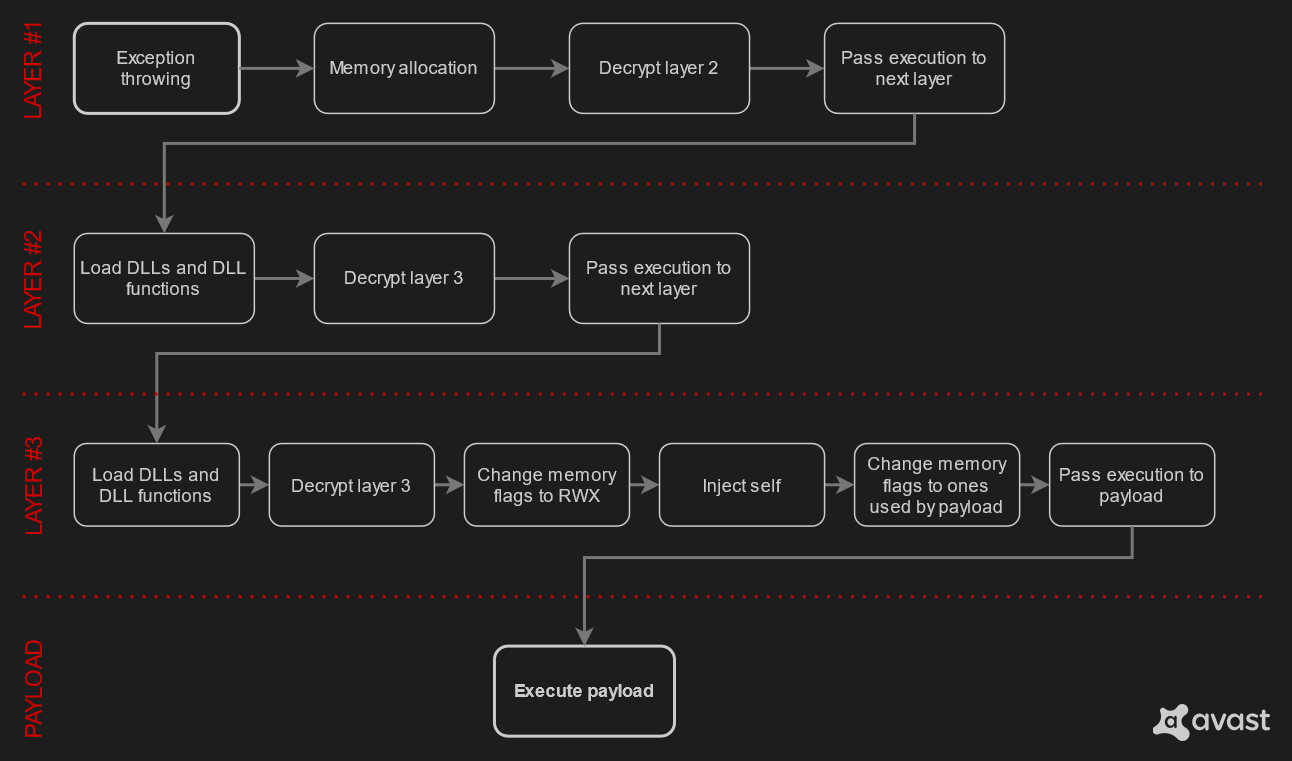
Layer 2 is a shell code whose ultimate task is to decrypt another layer. This process is not straightforward at all. The overview of what happens on layer 2 can be seen on image below, but the “Decrypt layer 3” bubble hides quite a complicated process of decryption. The layer 3 is decrypted in parts, but the decryption happens on another sublayer of the layer 2, in shell codes. As if it’s not enough, even these shell codes are decrypted in small parts and then put together to form a decrypt sequence.
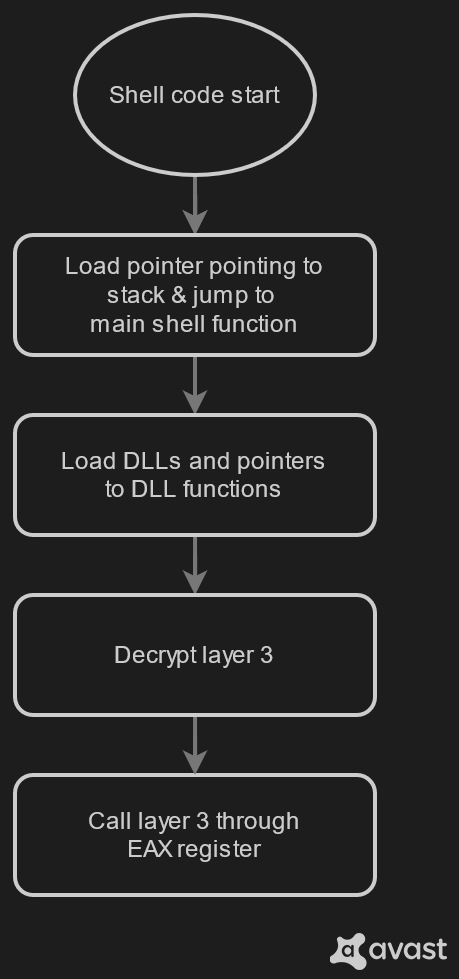
Finding DLLs and functions
As a first thing, OnionCrypter loads pointers to kernel32.dll. It uses TIB (Thread Information Block) to find the Process Information Block and there is a pointer to a structure (PEB_LDR_DATA) that contains information about all of the loaded modules in the current process. By searching this structure, OnionCrypter finds the base address of kernel32.dll.
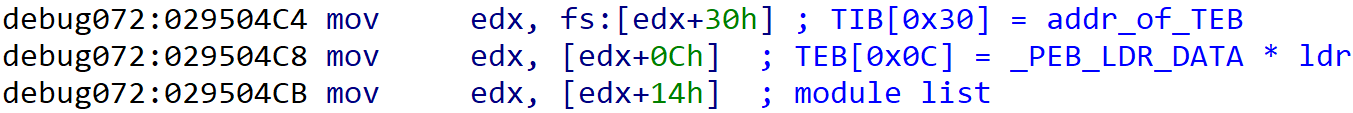
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
When OnionCrypter has the base address of kernell32.dll, it loads the address of the Export Table, which is well known. Then OnionCrypter iterates through the Name Pointer Table containing names of DLL functions. OnionCrypter calculates the CRC32 from every function name and compares that number to one received as a hard-coded parameter. When there is a match, an iterator value is used to find the function’s ordinal number in the Ordinal Table. With this number it is possible to look up the function’s address in the Export Address Table. Even if this method is known, OnionCrypter tries to hide what it’s loading by using pre-calculated CRC32 numbers instead of strings with function names.

8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
As a first function, OnionCrypter loads GetModuleHandleA. With this function it can then load advapi32.dll and ntdll.dll. In the next steps the program loads multiple functions from DLLs and stores them in the same memory space, where shell code is running. Fixed storage is created for that.
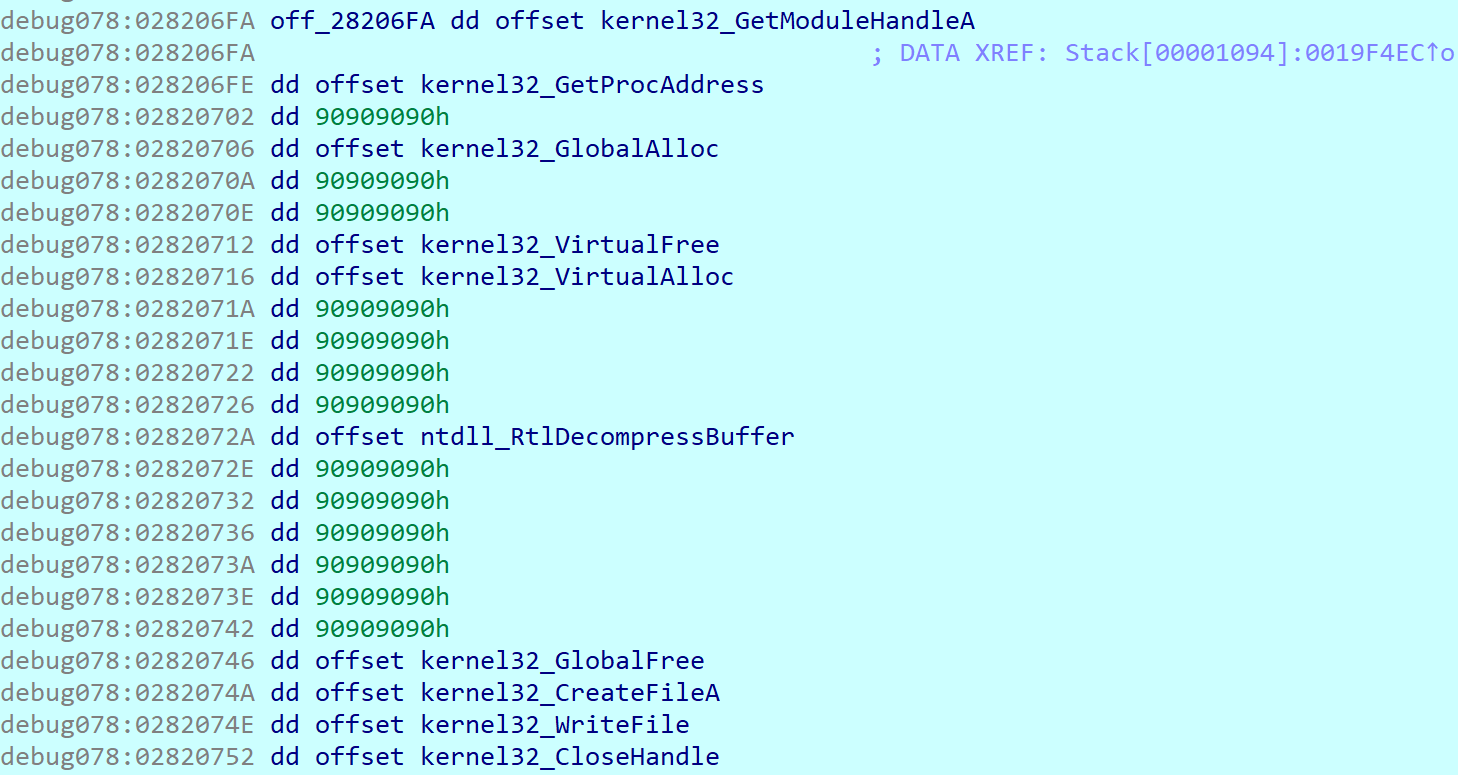
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
Decrypting next layer
Now shell code running on layer 2 starts decrypting layer 3. The structure of decryption is complex. At the highest level there is a big allocation of memory and a loop. Inside this loop is data decrypted in small chunks and copied into big memory, but it is not as simple as it seems.
Before that data chunk gets decrypted, the program first does one VirtualAlloc of size 0x1000 bytes and with RWX flags. After that, the program starts decrypting pieces of data with size of 16 bytes and putting them together. This is accompanied by such a large number of memory allocations that hooking allocation functions is useless (and annoying).
After decrypting and joining the pieces with the size of 16 bytes, data is copied to VirtualAllocated memory. As it turned out, the data is another shellcode, which consists only of a decrypt loop. This shell code is called and decrypts some data from layer 2. Then the decrypted data is transformed again by another function and copied into memory, whose address is returned.
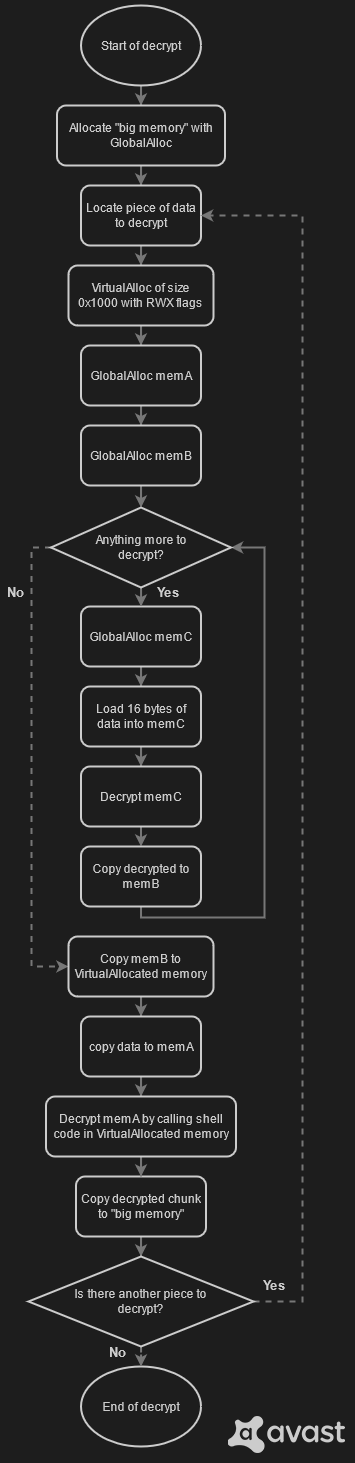
OnionCrypter has an option to compress data (or just some parts of data) with the RtlCompressBuffer function. This compression is used before encryption. During the decryption process chunks of data are decompressed after they are decrypted, but before they are merged with other chunks.
When all pieces are decrypted and joined, execution is passed to the place where the decrypted data is stored and the crypter starts execution of layer 3.
Layer 3
This layer is quite similar to the previous layer. At the beginning the same trick as described before is used to load some important API functions. This time the shell code loads even more functions than before.
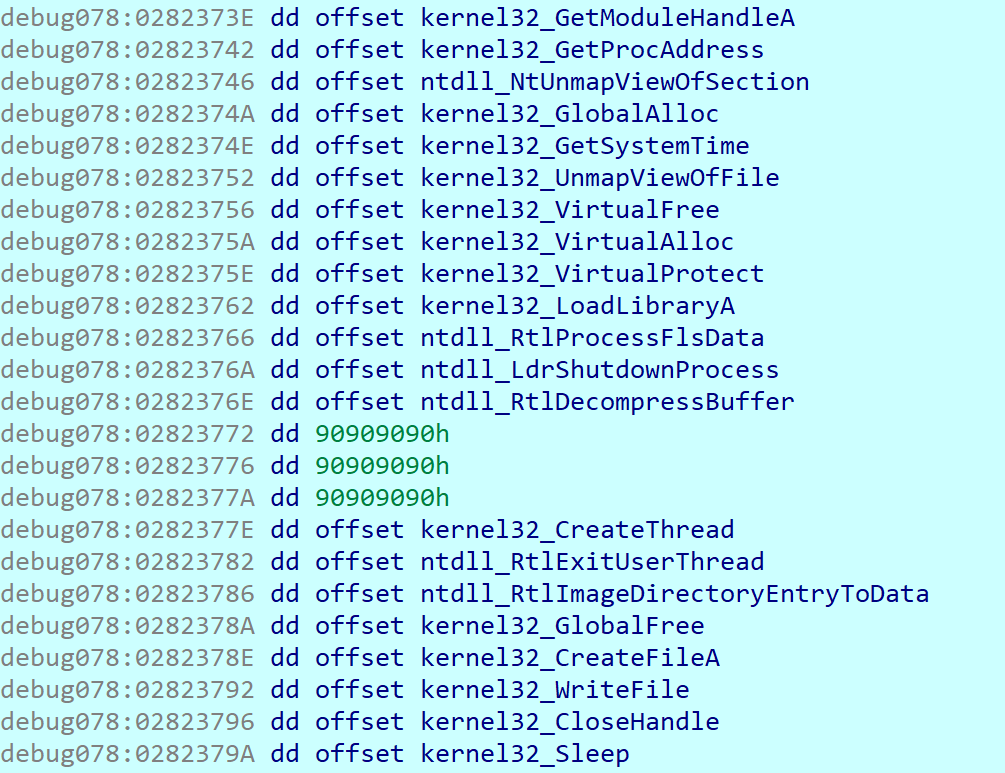
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
Even when these function pointers are loaded, they are not necessarily used. Some samples use RtlDecompressBuffer and some do not. The most probable cause of this is that OnionCrypter offers options like “additional compression” or “sleep”, which the user can choose when encrypting.
Decryption of the data is the same as in the previous layer. After decryption, OnionCrypter calls the VirtualProtect function in a loop and changes permissions of memory starting from the base address of the program itself to R/W/X. After this change, OnionCrypter copies decrypted data and overwrites itself, including the PE header and following sections. Then the program changes back memory permissions using VirtualProtect to ones that seem legit.
In the end, OnionCrypter finds the entry point in the new PE header and passes execution there. This is the point where the payload which is now injected into the crypter process starts running.
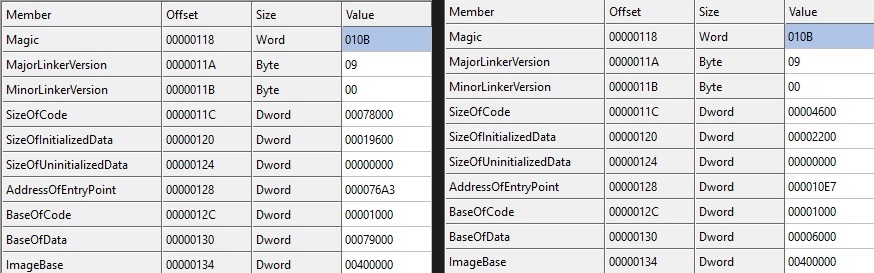
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
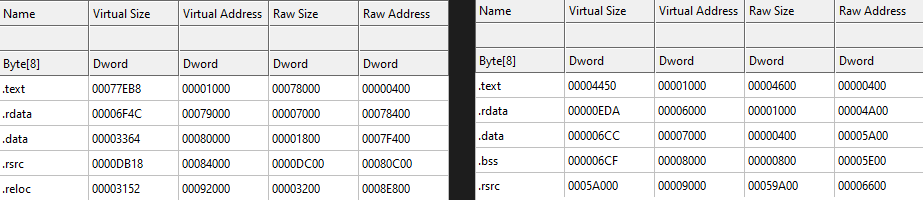
8B85A4D9DF1140D25F11914EC4E429C505BD97551EDE19197D2B795C44770AFE
Conclusion
OnionCrypter is a malware family which has been around for some time. Combined with the prevalence of this crypter and the fact that samples have such a unique first layer it’s logical to assume that crypter wasn’t developed as a one time thing. On the contrary, according to analysis of multiple samples and their capture date, it was possible to see multiple versions of some parts of OnionCrypter.
Across all of samples these main features of the Onion crypter stay the same:
- The three layer architecture
- Unique first layer with a lot of junk code
- Existence of the “main” function on layer 1
- General purpose and functionality of layer 2 and layer 3
On the other hand these are some of the things that may vary between samples from different versions:
- The decrypt algorithm of the second layer – There can be found simpler and also more complicated decryption algorithms used to decrypt the layer 2, as was described in previous sections. It is improbable that authors would come up with a complicated algorithm and then change it to something simple, just to make analysis easier. That is why it is possible that this part of OnionCrypter was updated with newer versions.
- The location of the “main” function – In older samples the “main” function on layer 1 generally can be found very easily, because it is the
WinMainfunction, which is the user-provided entry point of the application. This was changed in newer versions, because the majority of recently captured samples have quite a simple and shortWinMainfunction and the “main” function can be found as one of the other functions. - Structure of layer 2 and layer 3 – Even though these layers can be found in all samples of OnionCrypter and always serve the same purpose they may differ in implementation. As an example there are versions, which are loading less DLL functions. Also in some older versions the loading of DLL functions is not a standalone function. Based on the analysis, the internal layers have been reworked a bit to make the layers more complex, to add new features and to make the decryption process more complicated and obfuscated.
- Injection of the final payload – Although the majority of samples are using the technique of self-injection described in the previous section, there were cases where the decrypted payload was injected into a new process created in a suspended state. This technique is analogous to the self injection, but is done using a combination of functions
CreateProcessInternalW,VirtualProtectEx,WriteProcessMemoryandResumeThread.
This blogpost covered techniques discovered in both older and new versions of OnionCrypter. The whole process of decryption and execution of payload was described for the most complex and the most obfuscated versions, which can be considered to be the newest and the most difficult to analyze.
Indicators of Compromise (IoC)
- Hashes: https://github.com/avast/ioc/tree/master/OnionCrypter/samples.sha256
- List of the most common event names: https://github.com/avast/ioc/tree/master/OnionCrypter/event_names.txt
Appendix
- Repository: https://github.com/avast/ioc/tree/master/OnionCrypter
- IDAPython script for extraction of event names from samples: https://github.com/avast/ioc/tree/master/OnionCrypter/extras/extract_event_names.py


